

Se poate rula local, pe Windows 11, un model LLM llama 3.1 fără să fie nevoie de cine știe ce configurație de gaming? Spre surprinderea mea, răspunsul e DA! Ai nevoie de un laptop Copilot+ – pentru că am în teste un Asus Vivobook S15 Snapdrgon X Elite, l-am pus pe el la treabă cu rezultate peste așteptări.
De când cu febra asta a AI-ului am început să mă uit și eu mai îndeaproape peste subiect, inclusiv să descarc local diverse LLM-uri și să încerc să le modific. Fără putere semnificativă de calcul, pe sisteme mai puțin performante soluții precum AI Studio merg extrem, extrem de greu, probabil știți asta. Practic e imposibil să le folosești dacă un ai un super CPU sau un GPU optimizat.
Doar că de când Microsoft împinge intens ideea de sistem Copilot+ pe platforma ARM, ca soluție eficientă de a rula AI-ul Copilot, dar numai cu Windows 11, lucrurile încep să se schimbe și pare că există aplicabilitate pentru procesoarele NPU, dincolo de integrarea cu Windows 11 și AI-ul Copilot.
Am în teste un laptop Asus Vivobook S15 Copilot+ ARM (cu Snapdragon X Elite) și zilele trecute am avut o revelație: dincolo de faptul că e ușor, are un super display și că platforma ARM îi permite o autonomie bună, cu o performanță excelentă, fără zgomot, acest laptop poate fi folosit și ca instrument de explorare a AI-ului folosind soluții dedicate.
AI în NPU cu rezultate în timp real
Cine a studiat puțin domeniul știe că pe piață sunt câteva IDE-uri care permit interacțiunea cu diversele modele ce pot fi descărcate gratuit. E însă nevoie de ceva putere de calcul ca să își facă treaba bine, mai ales dacă e explorată ideea de personalizare a AI-ului.
Pentru că LM Studio nu are implementat în varianta standard suportul pentru folosirea NPU-ului de pe sistemele Copilot+ ARM, folosirea sa pe un sistem Copilot+ ARM e puțin cam anevoioasă. Am văzut că se poate (Scott Hanselman a făcut un demo cu așa ceva acum vreo 2 luni), dar pentru moment se mișcă greu de tot. Răspunsul la întrebări ceva mai complexe (de exemplu rezolvarea unei probleme de matematică) e dat în câteva minute de LM Studio 0.3.6, folosind la maxim CPU-ul de pe un laptop Copilot+ ARM, cu tot cu un model optimizat.
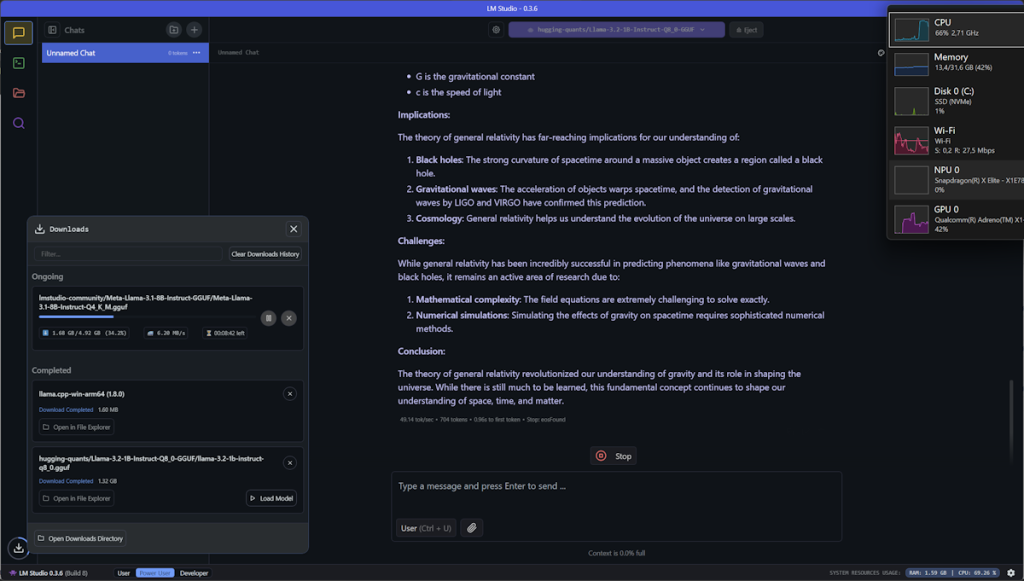
Anything LLM cu suport NPU
Căutând informații despre cum poți folosi modele LLM pe laptop-uri Copilot+ ARM care să pună în valoare NPU-ul am dat despre un anunț destul de proaspăt: IDE-ul AnythingLLM integrează Qualcomm QNN ce permite folosirea modelelor LLM cu suport NPU pe sisteme Snapdragon X, adică fix ceea ce am eu în Asus Vivobook S15.
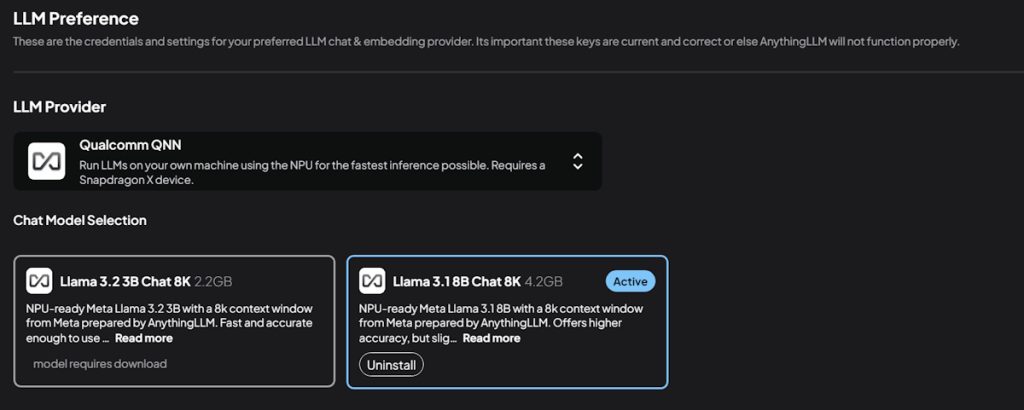
L-am dat jos de aici, l-am instalat (atenție că e atât de nou încât Microsoft încă nu l-a adăugat în lista de programe valide și implicit o să vă blocheze instalarea!) și am început să mă joc cu el. Interfața e relativ simplă: odată ce ai dat drumul la IDE, îți creezi un workspace în care îți alegi un Workspace LLM Provider, apoi descarci LLM-ul pe care vrei să îl folosești (și care e suportat de acel provider), setezi prompt-ul de început și te poți juca cu modelul.
Entuziasmat, i-am dat drumul rapid la o primă configurare cu setarea standard de provider AnythingLLM și llama:latest și m-am mirat că nu merge direct pe NPU și în schimb rupe CPU-ul. Care e faza?
Ca de obicei, fără acel RTFM nu ajungi nicăieri – studiat puțin documentația ca să mă prind că doar provider-ul Qualcomm QNN aduce suportul pentru NPU. Zis și făcut: am creat un nou workspace, am ales provider-ul Qualcomm QNN și am descărcat cel mai mare nodel llama 3.1 disponibil și am reîncercat.
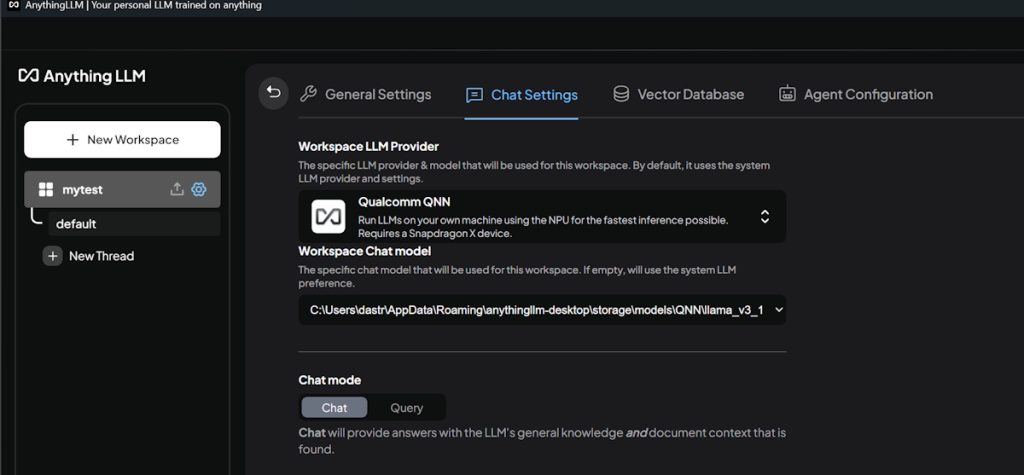
Sincer să fiu, mă așteptam să meargă, doar că nici de data asta nu am reușit: un mesaj de eroare sec care mă anunța că ‘QNN engine is offline’ sau că nu poate porni. O căutare pe net (și nu ChatGPT sau Copilot) îmi arată că dezvoltatorii știu că e o problemă , raportată deja pe Github-ul lor și că lucrează să o rezolve.
Uitându-mă prin loguri am văzut că de fapt problema mea nu are fix aceleași simptome (log-ul era gol) am mai încercat ceva: din setările AnythingLLM am ales ca engine implicit Qualcom QNN cu modelul llama 3.18B. Apoi mi-am făcut un nou workspace, am lăsat setarea implicită pentru egine și … supriză plăcută! AnythingLLM mergea acum pe NPU și chiar foarte bine, eu fiind pe baterie, cu setarea de optimizare a consumului de energie activă.
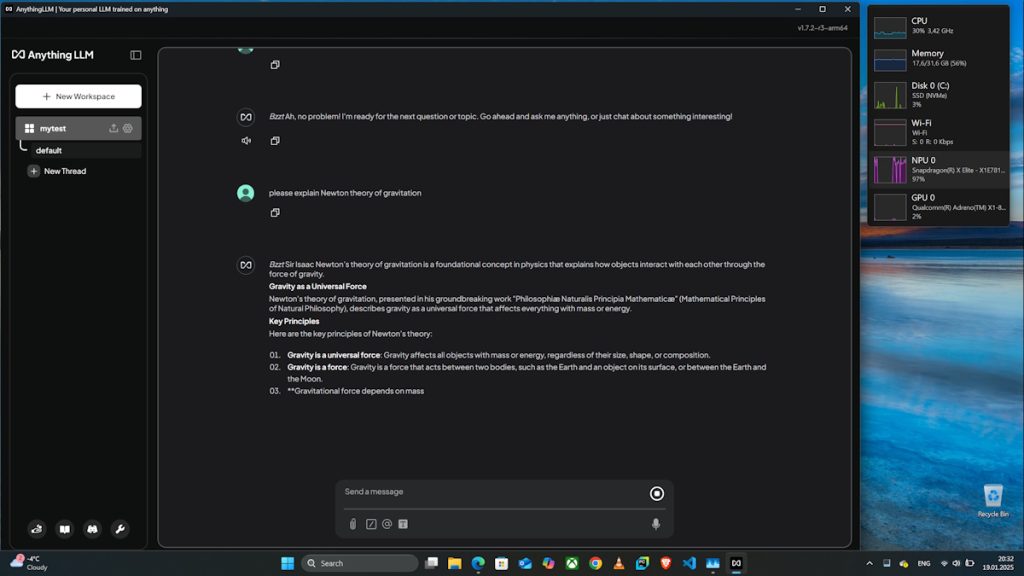
M-am distrat cu câteva întrebări la care răspunsurile au venit instant, inclusiv cu comenzi vocale (poți descărca Whisper, merge doar în limba engleză). Și astea în contextul în care CPU-ul stătea nemișcat undeva la 30% și toată interacțiunea cu LLM-ul se făcea folosind NPU-ul.
E un lucru bun, în ciuda faptului că modelul disponibil pentru folosirea cu NPU e doar un llama 3.18B, destul de vechi. Sper ca în curând să văd suportul și pentru alte LLM-uri, inclusiv versiuni mai noi de llama.
Până atunci am un lucru pozitiv: sistemele ARM Copilot+ încep să fie utile și să pună în valoare harwdare-ul dedicat pentru zona AI și dincolo de integrarea cu Windows 11. Înseamnă că e loc de mai bine.
Pe măsură ce mai testez ecosistemul Windows 11 ARM cu Copilot+ o să vă mai spun cum stă treaba, până acum surpriza e foarte plăcută – și vă spune asta un utilizator de Windows de peste 30 de ani, care a avut interacțiuni multe (unele neplăcute) cu experimentele Microsoft pe ARM și care în ultimii 2 ani a folosit aproape exclusiv platforma MacOS. Mă bucur să văd că Microsoft pare să se fi trezit și că încearcă să investească și aici, dar mai tar emă bucur să văd că producătorii de laptop-uri au înțeles că viitorul e în ARM (da, dictat de Apple) și aduc soluții faine.
Astea fiind zise, vin în curând cu review-ul de Asus Vivobook S15 Copilot+ înc care povestim mai multe.

